Why you should use Avro and schema registry for your streaming application
A common problem in streaming applications
Kafka is a fast, scalable, durable, and fault-tolerant publish-subscribe messaging system which is widely adopted by enterprises.
Kafka has the nature of zero-copy, which does not load data into memory and makes Kafka operate fast. When Kafka gets data from a producer, it takes bytes as input and publishes them without parsing or even reading the data. This zero-copy principle reduces the consumption of CPU and memory bandwidth, improving performance especially when the data volumes are huge.

But what if the producer starts sending bad data? What if the producer has been changed and has a different schema than consumers? What if the field you’re looking for doesn’t exist anymore?
You consumer will break and so will your streaming application.
So what should we do to solve this issue?
- Manually maintain schema changes and handle exceptions (this may easily diverge from reality).✖️
- Adopt a data format and enforce rules that allow you to perform schema evolution. (Schema registry will help you achieve this). ✔️
Why we need Schema Registry?
Schema registry allows producers and consumers to update independently and evolve their schemas independently, with assurances that they can read new and old data.
It stores a versioned history of all schemas, allows schema evolution and provides compatibility checks to ensure that the contract between producers and consumers is not broken.
Schema registry also provides reusable schema, enabling relationship between schemas and generic format conversion.
To enable schema registry, we also need a self describable and compact data format for Kafka which can support both schema and schema evolution.

Why Avro?
ORC, Parquet, and Avro are all machine-readable binary formats which support compression and schema evolution. However, since we are dealing with real-time streaming data, and we will use Confluence Schema registry later, Apache Avro becomes the best choice for us. For more information about the difference between these big data formats, check this link.
Apache Avro is a remote procedure call and data serialization framework which uses JSON for defining data types and protocols, and serializes data in a compact binary format.
- Avro is fully typed.
2. Avro is a compressed binary data format. Serialization makes it efficient in space.
3. Avro schema comes along with the data. The data without the schema is an invalid Avro object.
4. Avro has a concept of projection which supports schema evolution.
You can also embed documentation in the Avro schema. Embedding documentation in the schema reduces data interpretation misunderstandings, allows other team members to know about your data without asking you for clarification.
To give you a sense of what schema definition looks like in Avro, here is an example. Just a simple JSON object right?
{
"type" : "record",
"name" : "userInfo",
"namespace" : "my.example",
"fields" : [{"name" : "username",
"type" : "string",
"default" : "NONE"},
{"name" : "age",
"type" : "int",
"default" : -1},
{"name" : "phone",
"type" : "string",
"default" : "NONE"},
{"name" : "housenum",
"type" : "string",
"default" : "NONE"},
{"name" : "street",
"type" : "string",
"default" : "NONE"},
{"name" : "city",
"type" : "string",
"default" : "NONE"},
{"name" : "state_province",
"type" : "string",
"default" : "NONE"},
{"name" : "country",
"type" : "string",
"default" : "NONE"},
{"name" : "zip",
"type" : "string",
"default" : "NONE"}]
}In the example above, you can observe that there are three fields for each record:
- type − type field comes under the document as well as the under the field named fields. In case of document, it shows the type of the document, generally a record because there are multiple fields. When it is field, the type describes data type.
- namespace − This field describes the name of the namespace in which the object resides.
- name − This field comes under the document as well as the under the field named fields. In case of document, it describes the schema name. This schema name together with the namespace, uniquely identifies the schema within the store (Namespace.schema name). In case of fields, it describes the field name.
Default value is used when reading instances that lack this field(optional).
Schema Evolution
There are 3 types of schema evolution for Avro.
- Backward: consumers with a new schema can read old data
- Forward: consumers with an old schema can read new data
- Full: when you have both Backward and Forward
Let’s explain these concepts. With Avro, when an application wants to encode some data, it encodes the data using whatever version of schema it knows about. This is writer’s schema. When an application wants to decode some data, it is expecting the data to be in some schema, which is reader’s schema.
The writer’s schema and the reader’s schema don’t have to be the same, they only have to be compatible. Avro resolves the differences by looking at the writer’s schema and the reader’s schema and translating the data from writer’s schema into reader’s schema.
For instance, if the application reading the data encounters a field that appears in the writer’s schema but not in the reader’s schema, it will be ignored. If the application reading the data expects some field but the writer’s schema does not contain a field of that name, it is filled in with a default value declared in the reader’s schema.
To maintain this kind of compatibility, you may only add or remove a field that has a default value. If you added a field that has no default value, new readers would not be able to read data written by new writers, so you would break forward compatibility. If you removed a field that has no default value, old readers wouldn’t be able to read data written by new writers, so you would break forward compatibility.
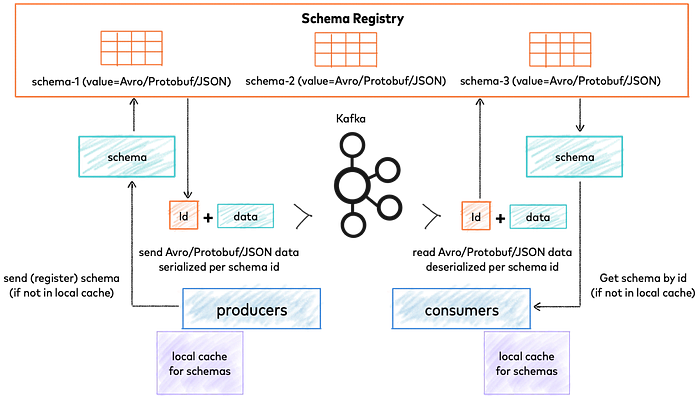
Confluence Schema Registry
Confluence Schema Registry allows you to define new data-model(subject), versions on that subject, retrieve and modify subjects and have your code access those schemas via an API.
It stores and retrieves schemas for Producers / Consumers, enforces backward, forward or full compatibility on topics.
You can either evolve the schema via UI or using the command-line tool.
Check out these tutorials for step-by-step workflow for using Confluent Schema Registry and Schema Registry CLI examples.
In a nutshell….
Schema Registry provides the missing schema management component in Kafka. Avro serializes data in a compact binary format and supports schema evolution. Confluence schema registry allows you to evolve the schema via API.
Using Avro and schema registry may require extra configuration in your infrastructure system but will protect your real-time application and give you long term benefits.
- Reliable development process
Keeping a registry of a versioned history of schemas allows you to check forward and backward compatibility of schema changes before any change is deployed.
- Simplify operational complexity
Now when you need to add a new column to a downstream database, you don’t have to coordinate tens of teams for that.
- Better control of data quality
You are provided with greater control over data quality, which increases the reliability of the entire Kafka ecosystem.
Ready to get started for schema registry?
Here are schema registry tutorials by Confluence:
Guide to install and configure Confluence Schema Registry
Happy Learning!
Reference
