Scale Kafka Consumers
Horizontally scaling and vertically scaling.
Key Concepts in Kafka
Apache Kafka is a publish-subscribe messaging system which lets you send messages between processes, applications, and servers. Applications which need to read data from Kafka use a KafkaConsumer to subscribe to Kafka topics and receive messages from these topics.
Reading data from Kafka is a bit different than reading data from other messaging systems, and there are few unique concepts involved. Let’s first review some of the key concepts in Kafka.
1.Topics
Similar to a table in database, topics is a particular stream of data. Topics consist of one or more partitions, ordered, immutable sequences of messages to which Kafka appends new messages.
2. Partitions and Offset
Topics are split in partitions. Each message within a partition gets an incremental id, called offset.

3. Brokers
A Kafka cluster consists of one or more brokers. Partitions are spread across these brokers. After connecting to any broker, you will be connected to the entire cluster.
4.Replicas
Topics have a replication factor to make sure if one broker is down, another broker can serve the data.

5. Zookeeper
Zookeeper manages brokers, helps in performing leader election for the partition.
6. Producer
Producers write data to topics.
7. Consumer
Consumer read data from a topic.
8. Lag
A consumer is lagging when it’s unable to read from a partition as fast as messages are produced to it. Lag is expressed as the number of offsets that are behind the head of the partition.
The time required to recover from lag depends on how quickly the consumer is able to consume messages per second:
recover time in seconds = messages / (consume message per second - produce message per second)What is Consumer Group?
Consumer can be grouped together for a given topic for maximizing read throughput. Each consumer in a group read from mutually exclusive partitions.

If all the consumer instances have the same consumer group id, then the records will effectively be load-balanced over the consumer instances and each consumer in the group will receive messages from a different subset of the partitions in the topic.
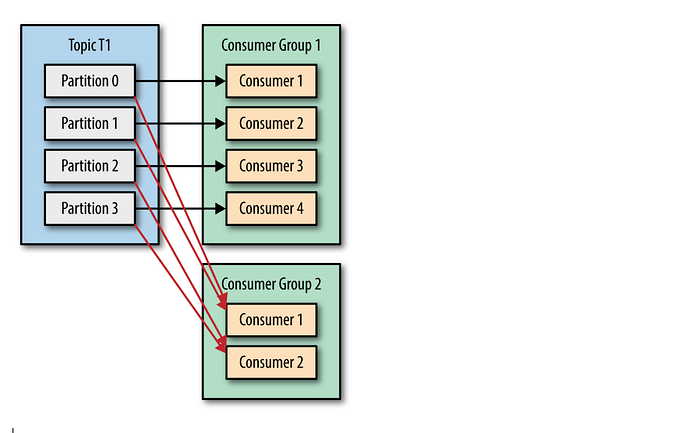
When to use different Consumer Groups?
When the consumers are performing different operations on the same topics, we should use different consumer groups.
For example, some consumers might update the downstream databases, while other consumers might do some real-time analysis with the data. In this case, we should register these consumers with different group-ids.
Why we need consumer parallel processing?
If you have a topic with four partitions and only one consumer in a group, that consumer would consume records from all the partitions.
This may work for you in some cases, but what if the rate at which producers write messages to the topic exceeds the rate at which your consumer application can process them? If you are still limited to a single consumer reading and processing the data, your application may be unable to keep up with the rate of incoming messages. In Kinesis, this latency is called iterator age. Obviously there is a need to scale consumer consumption from topics. Just like multiple producers can write to the same topic, we need a similar mechanism to allow multiple consumers to read from the same topic, sharing the data between them.
Scale data consumption horizontally
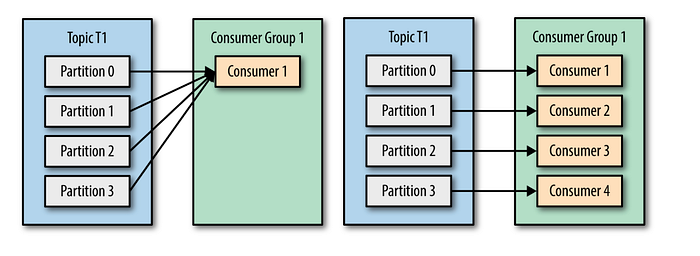
The main way we scale data consumption from a Kafka topic is by adding more consumers to the consumer group. It is a common operation for Kafka consumers to do high-latency operations such as writing to databases or a time-consuming computation.
If you know that you will need many consumers to parallelize the processing, you can plan accordingly with the number of partitions to parallel the consumer works.
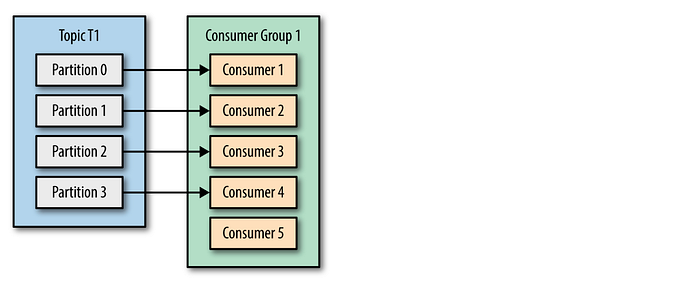
It’s also important not to have more consumers in a group than you have partitions. The extra consumers will just sit idle, since all the partitions are taken.
Partition Rebalance
what will happen if we add a new consumer to the group? The new consumer will start consuming messages from partitions previously consumed by another consumer. If it leaves the group, the partitions it used to consume will be consumed by one of the remaining consumers.
We call moving partition ownership from one consumer to another a rebalance.
Commits and Offsets
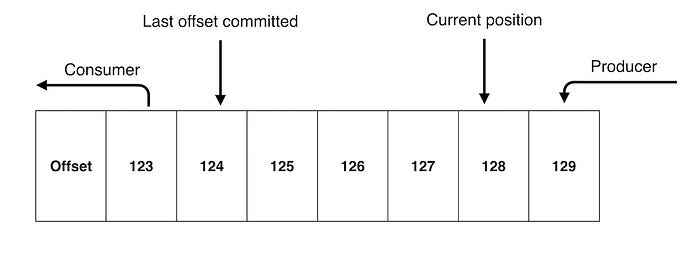
Current offset is the offset from which next new record will be fetched.
Committed offsets is the last committed offset for the given partition. Consumer produces a message to Kafka, to a special __consumer_offsets topic, with the committed offset for each partition.
If a consumer crashes or a new consumer joins the consumer group, this will trigger a rebalance. In order to know where to pick up the work, the consumer will read the latest committed offset of each partition and continue from there. We call this action of updating the current position in the Kafka partition a commit.
Vertical Scaling
What if horizontally scaling is not enough or our consumer number already reaches the number of partitions? If you are dealing with high volume data or your consumer is doing expensive calculation, this can be a common question for you.
Single-threaded model vs multi-threaded model
A typical single-threaded model could be: first, it retrieves records using the poll() method, and then it processing fetched records.
Because records are fetched and processed by the same thread, they are processed in the same order as they were written to the partition. This ensures the processing order guarantees.
For example, in AWS Kinesis with Lambda architecture, you can change the batch size which controls the maximum number of records that can be sent to your Lambda function with each invoke.
Multithreading is “the ability of a central processing unit (CPU) (or a single core in a multi-core processor) to provide multiple threads of execution concurrently, supported by the operating system.” In situations where the work can be divided into smaller units, which can be run in parallel, without negative effects on data consistency, multithreading can be used to improve application performance.
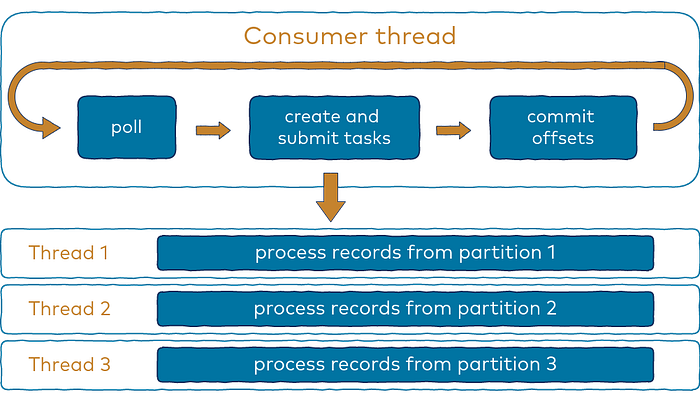
A multi-threaded model may be processing each message in a separate thread taken from a thread pool, while using automatic offset commits. However, a Multi-threaded model may cause some undesirable effects:
- Offset might be committed before a record is processed by consumers
- Message processing order can’t be guaranteed since messages from the same partition could be processed in parallel
Multi-threaded model is useful when the other system can accept such high load and when there is no dependency on the order of processing.
Conclusion
We have seen how Kafka consumer groups work and how we could horizontally parallelize consumers by sharing the same group-id. In this approach, scaling of consumers can’t go beyond the number of partitions. We can also use vertical scaling for consumers but we need to be careful of the change of processing order if we choose multithreading.
Can we apply theory to practice and make use of both horizontally scaling vertically scaling in a real case? Read my blog on reducing Lambda latency with Kinesis.
